Why Duplicate Data in Salesforce Is Impacting Your Profits, and How to Fix It
Published by Bryce Jones on November 16, 2022
You may already know that duplicate data is a problem, but each moment your salespeople spend fixing the data – instead of selling – affects their ability to perform. And what’s worse is that left alone, duplicate data doesn’t stagnate; it continues to grow.
The problem is that fixing data isn’t always easy, and Salesforce has limitations. For example, imagine that a customer downloads two different white papers. He enters “Robert Smith” with their work email for the first download and “Rob Smith” with their personal email for the second. As a result, two separate contacts are created, and two different salespeople are assigned to the contacts, wasting valuable resources and creating a fragmented customer experience.
Situations like this cost your organization time, money, internal conflicts and customer trust. And still, the duplicates continue to multiply. Consider that:
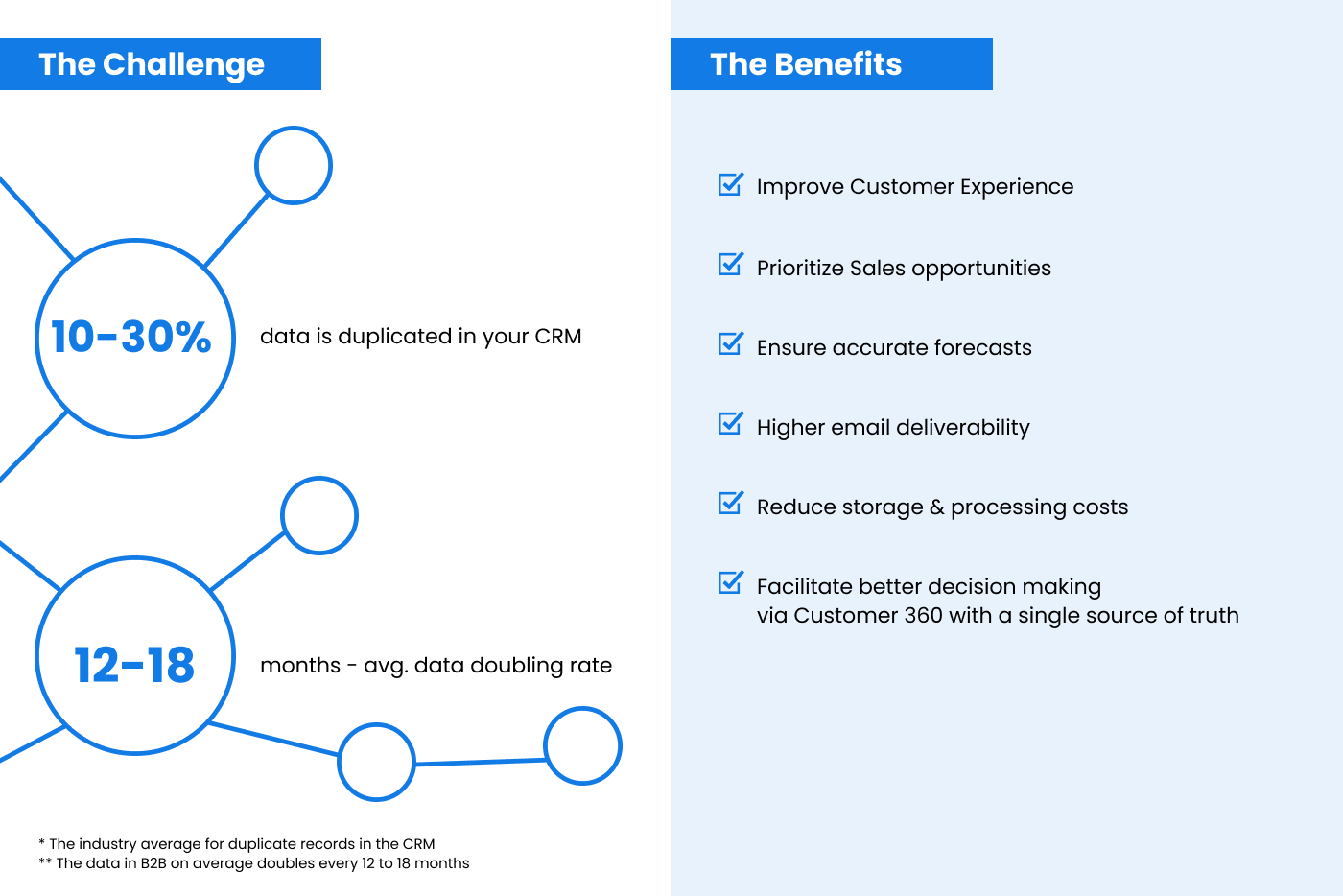
- Data doubles every 12-18 months on average.
- Duplicate records account for 10% to 30% of the data in CRM systems.
- Data decays up to 30% annually.
Maintaining accurate and real-time data can be a considerable challenge, but it doesn’t have to stay that way. When you understand Salesforce’s limitations and what to do about them, you can eliminate this barrier and empower your sales team to get back to selling.
Salesforce features and limitations
Salesforce has an out-of-the-box duplication management function designed to spot duplicates and help you manage them. The system relies on the following elements:
- Salesforce matching rule. This creates a specific criterion designed to spot duplicate records. Three standard matching rules are used: one each for person accounts, business accounts, and contacts and leads. There are two methods for using these rules: “exact” and “fuzzy.” The exact method uses a complete string comparison for the field, and the fuzzy method uses a matching algorithm for specific fields.
- Duplicate rules. Additionally, Salesforce relies on duplicate rules, which dictate what action will occur when a duplicate record is found. The rule can alert the user or block the user from creating or modifying the record.
Many challenges exist with these approaches, including the fact that not all fields support “fuzzy logic matching.” Additionally, an option doesn’t exist where you can reject the duplicate suggestion for a record. The ability to automatically process duplicates also doesn’t exist, creating long and time-consuming processing times.
A different approach to getting rid of duplicates
Machine learning allows you to correct duplicate data faster. However, data is complex, and sometimes a duplicate record exists for a good reason. For example, you might have a Mary Smith who is the sales manager of an organization. And then you might have a Mary Smith who serves on the board of directors of a different organization – same person, two different records. And in this situation, you want those records to remain separate. Dealing with this type of occurrence within Salesforce is complicated, but not with an AI-based tool.
An AI-based solution intelligently identifies duplicate content and learns from how users engage with those recommendations. Duplicates are detected faster, and the user can decide whether those records should remain separate or be merged.
An AI-based solution also helps with data decay. On average, 30% of your data decays each year, and to keep performing optimally, your salespeople need good data. An AI solution can check and enrich your data so that you have more complete fields and get better at deduping as time goes on. And you can still tap into your sales and marketing people’s contextual knowledge about data, such as the above situation of Mary Smith, to determine whether she really needs two records or one. A few key benefits of this type of solution include:
- Tapping into artificial intelligence’s ability to detect duplicate data more quickly and accurately.
- The flexibility to automate at a larger scale and process manually when appropriate.
- High performing models to handle tens of millions of records.
- The ability to customize fields and streamline how you’re working in Salesforce.
Spend less time on data, recapture lost resources
You need an effective way to clean up existing data duplication and mitigate the problem in the future. A comprehensive, easy-to-use AI solution helps you accomplish this by moving beyond Salesforce’s restricted duplicate management system. Instead, you can evaluate records without limitation using AI, spot duplicates as they come up, and manage them more efficiently via automatic merging, batch processing or manual review.
And as you get more proactive about duplicate data, you’ll save money and help your sales team spend less time managing data and more time creating the results you need to grow.
Want to learn more about Delpha?
![]()
![]()
![]()


