Duplicates: The Bane of Data-driven Companies
Published by Bryce Jones on October 3, 2022
10-30% of data in databases are duplicates. Bad data is costing each business $15 million on average every year
But duplicate data is inevitable and current market solutions are too expensive to implement right?
We disagree. This article explains how and why part of our data quality AI solution focuses on duplicate data.
What is a Duplicate?
In most cases, duplication arises when two or more database records represent the same entities, a problem present for over 20 years. The impact of duplicate or inconsistent records in databases can be severe, and general databases have led to the development of a range of methods for identifying such records.
Some approaches have been studied to parry the question, particularly machine learning techniques, widely used for finding duplicate records in general databases.
At Delpha, we offer an integrated solution in Salesforce that aims to improve customer business performance by helping users take the right actions.
The goal is to help employees improve the quality of data in Salesforce and ensure the application of processes by recommending the next best step and automating tasks.

MIT research revealed that 97 percent of surveyed businesses admit to having unacceptable data, and 50% of new data are problematic. Duplication is one of those contributing factors and the challenge for many solutions is detecting the duplicate as many are non-exact matches.
The value of a database is tied to the quality of the data it holds. For databases in general, the presence of duplicate or inconsistent records can have evident and severe effects. Companies tend to use their database as a searching tool, and duplications can cause migraines for all involved.
As an example, we can cite call centers: it is well known finding someone can be challenging due to duplication. The idea of automating the de-duplication of data is critical in business.
Delpha Strategy – Going Beyond Exact
Many solutions that are attempting to de-duplicate are based on Boolean methodologies where only exact values are identified and collected for merging and/or deleting purposes.
However, with the complexity and frequency of today’s data coupled with the human errors that can occur while working within databases, exact matches are not enough.
Below is an oversimplification of deduplication based on exact matches. You could think of each row as a different contact entry where each column represents different data, i.e. first name, last name, address, etc.
When deduplication occurs in an exact framework, it will only identify the contacts that match the specified criteria. Below it would be based on the first column so the result would only be identifying the first two entries as potential duplicates and treating the third as a unique contact.

At Delpha, we engineered a new solution that adopts Fuzzy Logic to cast our net out wider to ensure a greater number of duplicated data is identified. Following the simplified diagram from above, fuzzy logic would then take in contextual information to assess where or not a contact is a duplicate.
In this example, the value in the “E” field could be an abbreviation or a shortened version of the first name (maybe even a nickname) which would have been missed in an exact filter. However, the fuzzy logic is able to analyze the other fields and determine a probability that the contact is a duplicate depending on the amount of similar information.

Now for those who want to go deeper, I am going to delve into more of the technical concepts behind these concepts that we have built into our product.
Fuzzy Duplicate method – The Levenshtein Distance
The Levenshtein distance is a metric to measure how apart are two sequences of words. Specifically, it measures the minimum number of edits that you need to do to change a one-word sequence into the other.
These edits can be insertions, deletions, or substitutions. Vladimir Levenshtein, who initially considered this metric in 1965, named it. The formal definition of the Levenshtein distance between two strings a and b can be seen as follows:
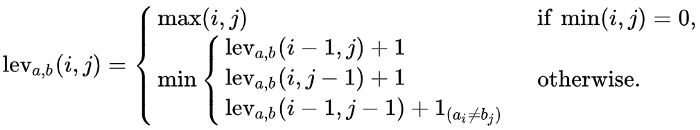
Figure 1: Levenshtein Distance Definition
Where 1(ai!=bj) denotes 0 when a = b and 1 otherwise. It is important to note that the rows on the minimum above correspond to a deletion, an insertion, and a substitution in that order.
It is also possible to calculate the Levenshtein similarity ratio based on the Levenshtein distance. This can be done using the following formula:
(|a| + |b|) − leva,b(i, j
|a| + |b|
where |a| and |b| are the lengths of sequence a and sequence b respectively. The edit distance calculation computation time grows non linearly with the token length. Treating the whole text field as one token may be very computationally intensive.
One way to optimize the problem and to convert the complexity to an almost O(n) is to abandon distance processing between two records, as soon as the distance between an attribute pair is found to be above a predefined threshold.
For example, if the distance between the name fields for two customer records is significant enough, we can skip processing the remaining attributes and set the distance between the two records to a large value.

Fuzzy Logic
Fuzzy logic is a form of multi-valued logic that deals with approximate reasoning rather than fixed and exact. Fuzzy logic values range between 1 and 0. i.e., the value may vary from entirely true to completely false.
In contrast, Boolean Logic is a two-valued logic: true or false usually denoted 1 and 0 respectively, which deals with fixed and exact reasoning. Fuzzy logic tends to reflect how people think and attempts to model our decision-making, leading to new intelligent systems(expert systems).
So, if we compare two strings using fuzzy logic, we would be trying to answer the question “How similar are string A and string B?” when using the Boolean Logic.
Various attribute types are supported for an entity, including integer, double, categorical, text, time, location, et cetera. Nearly for any pair of entities, distance is calculated between corresponding attributes. Attribute-wise distances are aggregated over all the attributes of an entity to find the distance between two entities.
One can enter a record into Salesforce in many different ways. The values in duplicate records may not precisely match but are similar. Using Delpha’s solution, you can perform a ‘duplicate check,’ which uses this fuzzy matching logic.
A duplicate check can analyze any object in Salesforce (not only the Lead, Contact and Account Object or Custom Objects) and present a clear report on all duplicate records. Using Fuzzy Matching, Duplicate Check will also list similar duplicate records: they don’t have to be the same.
One way to optimize the problem and convert the complexity to an almost O(n) is to abandon distance processing between two records as soon as the distance between an attribute pair is above a predefined threshold.
For example, suppose the distance between the name fields for two customer records is significant enough. In that case, we can skip processing the remaining attributes and set the distance between the two records to an immense value.
Machine Learning to the rescue

TF-IDF (term frequency-inverse document frequency)
TF-IDF is a statistical measure that evaluates how relevant a word is to a document in a collection of documents. It can be calculated by multiplying two metrics: the number of times a word appears in a document and the inverse document frequency of the word across a set of documents.
It has many uses, most notably in automated text analysis, and is very useful for scoring words in machine learning algorithms for Natural Language Processing (NLP). TF-IDF was invented for document search and information retrieval.
It works by increasing proportionally to the number of times a word appears in a document but is offset by the number of documents that contain the word. So, words commonly used in documents like “this”, “what”, and “if”, rank low even when appearing many times, since they do not carry much of a meaning in that file.
One of the metrics to calculate TF-IDF is the term frequency of a word. There are several ways of measuring this frequency, with the simplest being a raw count of instances a word appears in a document. Then, there are ways to adjust the frequency, by length of a document, or by the raw frequency of the most frequent word in a document.
The inverse document frequency of the word across a set of documents. This means how common or rare a word is in the entire document set. The closer it is to 0, the more common a word is.
This metric can be calculated by taking the total number of documents, dividing it by the number of documents that contain a word, and calculating the logarithm. So, if the word is very common and appears in many documents, this number will approach 0. Otherwise, it will approach 1.
Multiplying these two numbers results in the TF-IDF score of a word in a document. The higher the score, the more relevant that word is in that particular document. To put it in more formal mathematical terms, the TF-IDF score for the word t in document d from the document set D is calculated as follows:
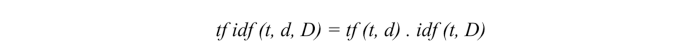
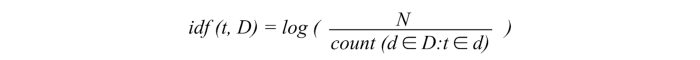
So why would we use TF-IDF?
Machine learning with natural language faces one major hurdle – its algorithms usually deal with numbers, and natural language is, well, text. So we need to transform that text into numbers, otherwise known as text vectorization.
It is a fundamental step in machine learning for analyzing data. Different vectorization algorithms will drastically affect results, so you need to choose one that will deliver the results you want.
We can use this method in a way to complete the duplicate record problem. The similarity between records is now translated into cosine distance between vectors and takes values between 0 (perfect duplicates) and 1 (totally dissimilar records).

To sum up
Duplicate data can harm all areas of business. We live in a world of big data. From the complex and highly-skilled industries such as pharmaceuticals and biotech to the fast-paced and massive sectors such as marketplaces and e-commerce, all industries have an incredible amount of information to process.
It is incredibly inefficient to try processing all this data manually. The process will take much time, human labor, and, of course, costs. That is why businesses all over the globe start implementing data matching services in their workflows.
Computers can process information better and faster than humans, especially since the machine learning industry evolves continuously and quickly. The technology gets more advanced every day offering companies better solutions, considering the quantity of data growing daily, using the de-duplicate algorithm to solve the problem and even automate it.
It’s time to let machine learning assist in your data quality improvement strategies.
Want to learn more about Delpha?
![]()
![]()
![]()


