
AI for Salesforce Deduplication: Manage Duplicates More Accurately and Prevent Future Creation
Published by Bryce Jones on October 3, 2022
The purpose of this post is to look at current strategies & tools to dedupe data in Salesforce today, understand the limitations of these current tools and demonstrate how AI can surpass these restrictions.

Duplicates have a very negative impact on businesses’ data quality and operational success. They arise from a variety of sources including human error, legacy data, mass imports, tech stack integrations, and lead capturing CTAs. Left unmanaged, they can split up our contact’s engagement details preventing your sales operations from having a single source of truth on each valuable customer record.
In any CRM, the data doubles every 12-18 months on average, and duplicate records can account for 10-30% of your CRM. Throw in another reality that data decays up to 30% annually and here we can see that our problem in maintaining accurate data needs to involve real-time and continuous attention to prevent data quality from falling behind.

There are traditional solutions to the duplicate challenge from manual data removal and matching rules to utilizing deduplication tools or platforms. We will discuss the current strategies and tools to deduplicate data inside Salesforce today, but then highlight the limitations that still exist and argue why it’s time to let AI resolve these problems. The key benefits to deduplicating data with AI are:
- Faster detection
- More accurate results
- Preserving contextual information into the decision process
- Safeguard against new duplicate data and data decay
AI can empower users to resolve the duplicate problem and ultimately improve the data quality of their company. Before we get into these benefits, it’s important to first understand the problems and costs that duplicate data is causing for your organization.
The Costs of Duplicate Data
1. Revenue loss
Inadequate data is responsible for an average of 12% decrease in revenue and costs $3 trillion a year for US businesses. Never forget the GIGO concept – if the input is poor, then the outcome will also be poor. These are huge financial losses that are holding back businesses from achieving greater success.

2. Wasted resources
Duplicate data wastes marketing budgets, inflates the storage and reconciling costs, and causes an immense economic loss due to a worsened customer retention. Forrester has estimated that 21 cents of every media dollar is wasted as a result of bad data (that’s about $16.5 million on average for enterprises).
3. Stalled Productivity
Deduplication of records, whether manually or with a tool, requires much time on mundane data tasks or training. All teams are bogged down by removing bad quality records – 80% of data scientists’ time, 32% of marketing teams’ time, over 50% of sales reps’ time. The less efficient the teams are, the less profitable your business is.
4. Missed opportunities
Whether prospecting or offering a solution to an existing client, accurate and relevant data is required. Only 13% of customers believe that offers made by salespeople meet their needs. It happens because 82% of sales reps are unprepared for cold calls due to inadequate or insufficient information. The lack of prioritization of efforts leads to missed opportunities.

5. Reputation Damage
Businesses report that bad data negatively affected 54% of their customer relationships. No wonder inaccurate and duplicate records confuse CSMs when they want to develop a helpful solution for a client. If the history of a consumer’s purchases is unclear or repeated, how is it possible to offer something relevant? As a result, customer satisfaction rates fall leaving a negative impression on the whole brand’s image.
Not only do these costs affect the business as a whole, but also the work of each department.
Marketing Struggles with Bad Data.
Duplicate data leads to a waste of the marketing budget and a worsened ROI. On average, 26% of marketing campaigns suffer from poor data quality.
With duplicates, you risk sending email campaigns or discounts to the same addresses, which will not only be a loss of resources but a customer dissatisfaction.
Imagine receiving the same piece of content twice a day; wouldn’t it make you want to unsubscribe or mark it as spam? Not to mention that it would just seem very unprofessional.
The marketing reports will also lack accuracy since they will be filled with duplicate data rather than actionable insights. It is hard to successfully plan and execute the subsequent campaigns if the analyzed reports do not represent reality.

With Bad Data, Sales Productivity is Reduced
Salespeople often input the same customers in the database. 33% of errors come from manual human entry. It happens that different reps may name leads or prospects in a similar yet not identical way. Before outreaching to customers, you risk wasting a lot of time removing the duplicate contacts from the database. Today many sales reps spend only 34% of their time on actually selling, while over 50% of their time goes to data quality management.
When preparing for calls, reps gather the necessary information to offer the best service. However, with duplicates present, there is a risk of client history loss and misinterpretation. The misalignment of communication leads to missed opportunities.
In the end, sales teams spend more time on data quality than on actual selling.
Customer Experience Suffers with Bad Data
Customer success teams need to better know their customers and this means having a better synchronization with sales teams. When customer success teams have access to the full picture, they will be able to provide better and more personalized service.
To increase your Customer Lifetime Value and Net Promoter Score, there is a need for a personalized, proactive approach to clients. The data, thus, needs to be accurate and clean. If CSMs are bogged down with duplicate removal, they lose precious time on data cleaning and not solving customer inquiries.
If a customer calls, he/she wants a fast and relevant solution. It will not be an easy task if the support team will struggle to find the correct record out of all the duplicate contacts.
Irrelevant and timely resolutions will lead to frustrated customers and the damaged reputation of your business.

Bad Data Affects Adoption and Productivity
The main problem with duplicate records and poor quality data in IT is the resources wasted on its removal. Data scientists are in high demand, but don’t come cheap so why would you want 60% of their time occupied with data cleaning? At the same time, marketers, sales reps, and CSMs will continue to work with inadequate records and make ineffective decisions.
Bad data might also decrease Salesforce user adoption, which leads to missed opportunities, worsened customer retention, loss of revenue, and failure to make insightful decisions. If data inputs are outdated or distrustful, CRM usage is less valuable for the employees and vice versa. If users insert invalid or inaccurate data, the adoption becomes hard.
If you want to increase productivity or the ROI in your CRM investment then it needs to begin with data quality. Better data will help build trust in the CRM and improve user adoption. With more usage, the full value of the productivity and investment in the platform will result. If you start the process with bad data, the opposite will occur and continue to fuel a negative spiral downwards towards CRM failure.
Duplicate data is a burden for your company in many ways, which is why it is essential to address this issue with a helpful solution. Many admins and data stewards are relying on the Salesforce Duplicate Management tools to help mitigate the problem, however, we will highlight the key features and limitations and extend the conversation to how AI can surmount these limitations.
How Salesforce Dedupes with Duplicate Management
Salesforce provides an out-of-box Duplicate Management Functionality to identify and deduplicate data. Salesforce allows users to manage duplicates for the following objects:
- Business accounts
- Contacts
- Leads
- Person accounts
- Custom objects
Duplicate Management functionality relies on two main elements:
- Salesforce Matching rule
The matching rule defines the criteria to identify duplicate records. Salesforce provides three standard matching rules with one for person accounts, one for business accounts and one for contacts and leads. The two methods used for matching rules are:- Exact: Uses complete string comparison and can be most field.
- Fuzzy method: Uses matching algorithms and can be used on specific fields.
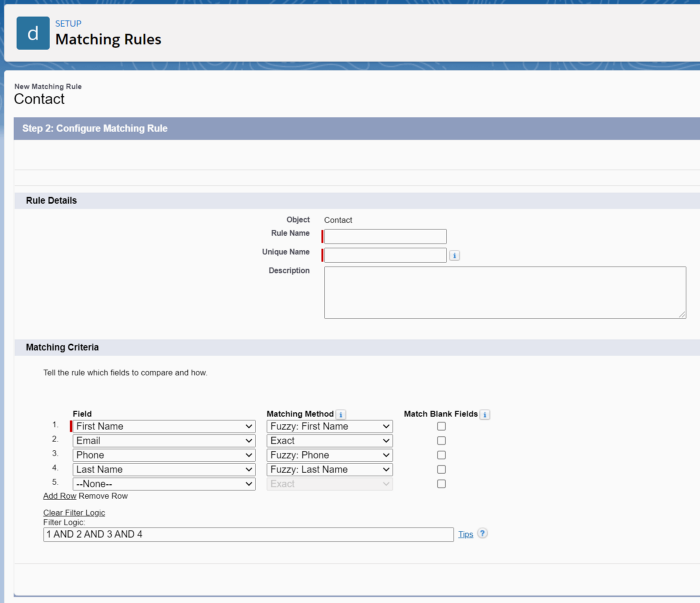
- Duplicate Rules
A duplicate rule determines what happens when a matching rule has identified duplicate records during a create or edit action. The rules can either alert or block the user from creating or editing the record.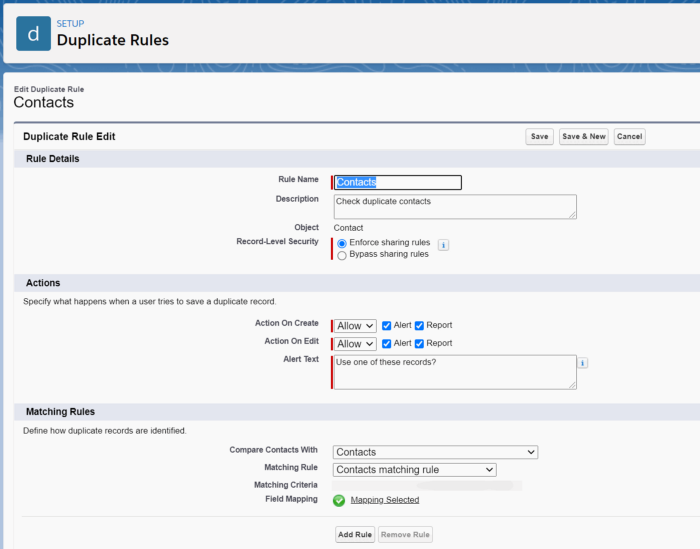
Additional features
- Duplicate Jobs:
The Duplicate Job produces a list of Duplicate Record Sets. From this list, you can compare and merge duplicate records. A job runs one matching rule at a time. However, the functionality is available only on ‘Performance’ and ‘Unlimited’ editions of Salesforce. Duplicate jobs can run on custom objects but can’t compare and merge the duplicates. - Duplicate Reports:
The Duplicate report helps you identify and review duplicate contacts. The Report option on the duplicate rule creates a record in the Duplicate Record Item and Duplicate RecordSet objects.You can create a custom report type with the primary object being the object you want to identify potential duplicates and the secondary object being Duplicate record items. Duplicate reports help you to identify false positives and redefine matching rules.
Limitations of Salesforce Duplicate Management that Affect Accuracy and Productivity
- Not all fields support fuzzy logic matching.
- There is no option to reject the duplicate suggestion for a specific record. (There is no feedback loop)
- You can only merge records (up to 3 at once). You cannot copy fields from potential duplicates.
- There is no possibility to define a threshold score on matching algorithms manually.
- If the duplicate matching rule is set for Leads, then Web-to-Lead submissions that match the duplicate rule will always be blocked.
- Unable to batch process objects other than Lead, Contact, and Account.
- Large processing is time-consuming and recommended to look for external tools.
- No support for batch jobs that involve cross objects.
- Unable to automatically process duplicates.
Key Differences Between Salesforce and Delpha
| Duplicate Feature | Salesforce | Delpha |
|---|---|---|
| Manual merging | Max 3 records | Unrestricted |
| Customizable matching
threshold |
No | Yes |
| Preserves all data (ex. all web-to-leads) |
No | Yes |
| Automatic processing of duplicates | No | Yes |
| Large data | Yes, but takes time | Yes |
| Feedback loop – Reinforced learning | No | Yes |
| Detection Applied to Multiple Orgs | No | Yes |
| Entity Matching (define relationship between similar accounts, ie subsidiaries) | No | Yes |
The majority of Admins mention they rely on the Salesforce Duplicate Management tools as their primary source of deduplicating data.
However the problems that continues to exist using this methodology can be summarized into the following categories:
- Long processing times – loss of productivity when CRM has many records (>10,000).
- Accuracy challenges – Large companies can have complex databases and multiple orgs that lack the ability to have a holistic approach to processing duplicates. Rule-based approaches also present their own execution challenges from detection and efficiency.
- Feedback – without human input, important data and context can be lost. Batch processing removes the human from the decision process and can result in loss of contextual knowledge.
The Benefits of an AI vs. Rules-based Approach to Deduping Data:
The advances of machine learning equip us with the ability to correct our duplicate data more efficiently and effectively. Our data in our databases are complex and sometimes there’s a need for a duplicate to exist so utilizing a rule-based approach that performs using exact matching processes isn’t flexible enough for us to incorporate human insight into the cleaning process. For example, maybe you have a contact who is an employee at one company and a board member at another and for marketing purposes, you’d prefer to have two contact records.
Delpha is not only able to intelligently identify duplicate contacts, but also learn from how the user engages with our recommendations. When contacts are detected as duplicates, the user can ultimately decide whether or not they need to remain separate (management of the Homonyms) or how to merge the data, but also choose to stipulate that these contacts need to exist separately. This information trains our algorithm to remember these contacts as unique and won’t recommend them again. The Delpha approach gives companies the following advantages to tackling duplicate data:
- Better model to compute data faster
- State of the art/scalable processing architecture
- Optimized data pipeline
- Machine learning pipeline – no limit
- No more need for complex rule-setting
- Advanced AI to detect more accurate and relevant duplicates
- More comprehensive approach to detecting duplicates across all orgs
- Reduces time to compute large amounts of records
- Able to set thresholds
- Human input into the decision process
- The user interaction and decisions provide data for our ML algorithm to learn from the user to recommend more relevant and personalized actions. If the user decides two Accounts or Contacts are homonyms then Delpha will learn from that information and stop identifying it as a Duplicate case. The key is Delpha keeps the user involved whereas batch processing removes their involvement.
- Eliminates the problems associated with automated batch processing and creates new opportunities to better manage duplicates such as entity matching and definition.
- Maintains data quality in real-time and addresses data decay
-
- Delpha constantly checks domains and contact information to catch changes that need to be updated such as when companies merge or acquire others, contacts change jobs or titles, information is incorrect, etc.
Improved Detection for More Efficient Deduplicating
The limitations of rule-based or even fuzzy logic approaches require a hefty computational effort that grows exponentially with the size of your database. You will have to process the entire database to be able to produce a list of duplicates that are based on the rules you established. For example, if you have 100,000 contacts in your CRM then you have 4,999,950,000 unique pairs of data (100,000 x 99,000 / 2). It’s going to take time and significant computational effortTo conduct this computation in real-time.
Delpha created a blocking filter that intelligently identifies the potential duplicate records to the contacts the user is accessing. Many tools today will employ an exact-match or fuzzy logic method to identify the duplicates. However, this process is still confronted with the issue of when and what contacts to process. Our method segments the data based on relevancy and then applies our AI model to provide faster computation speeds that allow the user to receive relevant recommendations in real-time usage of Salesforce.
An additional benefit is our tool allows for continuous improvement and doesn’t require manual scheduling. Since Delpha is consistently preventing data decay, end users will be able to catch duplicates sooner. For example, if a new record is created for an existing contact due to a job change or acquisition, Delpha will be able to detect this as soon as the 2nd record is created. It’s finally about stopping bad data from entering your CRM and achieving a consistent quality of good data.
Innovative AI for More Accurate Detection of Duplicates
The previous section explained how Delpha is faster, but it is also more accurate. We engineered our AI to outperform the current deduplication methods on the market to make the process more efficient for the end user and/or data steward. We apply advanced algorithms that are able to make the detection using more objects and data to ensure the duplicate we push to the end user are more accurate and don’t miss any that a rules-based approach may miss.
Why Human Input is Important to Preserve in the Deduping Process?
Data is complex and so are our CRM databases. Automating the deduplication process with existing tools or rules within Salesforce doesn’t allow for flexibility. I discussed a couple of cases earlier when it might be appropriate for the database to have duplicate contacts, but the current tools and CRM features lack a feedback loop that can prevent duplicate results that have been rejected from showing up again.
With our recommendation system, Delpha learns from the end user when they signify a certain match is necessary and not a duplicate, and will not suggest this duplicate again unless a future change in the data triggers the need for additional review. When using Delpha, users get tailored recommendations that are relevant and accurate and the ability to stop wasting time and effort scanning lengthy results pages for a specific duplicate.
Effective Duplicate Management Requires More Than Scheduled Fixes
The overall goal of Delpha is to enable your teams with the right solution to build and maintain high-quality data. Temporary solutions like batch processing or one-time fixes don’t resolve the fact that data will inevitably decay and bad data will return. Those bad data will enter into your data pipeline and incur negative effects on the business in terms of wasting resources, lowering employee productivity, distorting dashboards and predictive analyzes, and lowering adoption.
The game we want our clients to play is to stop duplicates from accumulating. The advantage of our solution is the AI is built to evolve beyond setting up a complex rule-based structure but instead evaluate the records with machine learning to detect duplicates as they arise and guide the user to managing them efficiently. There might be an investment of time initially to process the existing duplicates depending on the quality of your database today, but Delpha’s distinguishing factor is once you elevate your data to high quality, it will be maintained at that level.
Our solution to preventing bad data is achieved by leveraging AI and human augmentation. Delpha is consistently taking data from the user profile, behavior on Salesforce, and interactions with our conversations to ensure that the data inside prioritized accounts is complete, accurate, and up-to-date. The process of improving data quality can scale much faster when all users are enabled with one, easy-to-use solution that is working in real-time. As data improves, adoption and productivity will increase, which ultimately will increase the ROI of your Salesforce investment and produce positive results on your bottom line. To remain competitive in today’s digital era, companies need to achieve and maintain high-quality data.
Want to learn more about Delpha?
![]()
![]()
![]()


